


Merhaba, bir seri olmasına karar verdiğim veri bilimi yazılımlarını incelediğim ve uygulama ile destekleyeceğim seriinin ilk yazısında Java ile yazılan ve Eclipse üzerine inşa edilen workflow tarzı görsel proglama ile veri bilimi ve yapay zeka uygulamaları hazırlanabilen KNIME uygulamasının kurulumu, çok kullanılan GNU/linux sistemler üzerinde yapılandırması ve bir makine öğrenmesi uygulamasıyla kullanımını inceleyeceğim. Hazırladığım uygulamayı kaydedip bir github reposunda paylaşmayıda planlıyorum.
KNIME
KNIME Analytic, Java ile yazılmış bir veri bilimi ortamıdır. Bu yazılım çeşitli düğümler kullanarak bir workflow şeklinde görsel programlama yapmaya imkan sağlar ve ileri seviye kodlama bilmeden bile bir veri madenciliği uygulaması geliştirmeye imkan sağlayan bir uygulamadır. Çok çeşitli ve zengin bir plugin merkezine sahiptir ve akademide de oldukça sık kullanılır. Görsel programlamanın yanında kullanıcının oluşturduğu scriptleri ve kodları da kullanabiliceği genişletilebilir bir veri bilimi platformudur. KNIME bir çok işletim sistemine kurulumu desktekleyen çapraz platform bir yazılımdır. İndirmek için linke tıklayabilirsiniz. Bu yazıda KNIME'ı sadece GNU/Linux dağıtımları için inceleyeceğim.
Yapılandırma
KNIME uygulamsının tar.gz uzantılı arşivini istediğiniz lokasyona extract edebilirsiniz.
~$ tar xvf knime-analytic-?.?.?.tar.gz -C /opt/knime
Dizin içinde KNIME'ın tüm kütüphane ve plugin dosyaları mevcuttur. Knime isimli bir binary dosya bulunur ve bunu kullanarak uygulamayı başlatabilirsiniz. Fakat çalışmak için java 'ya ihtiyacı vardır.
JAVA 11
KNIME Analytic Java 11 ve daha üstü sürümlerle çalışıyor. Bu sebeple KNIME için openjdk-11 veya openjdk-latest paketlerinden birini kurabilirsiniz. Kullandığınız dağıtıma göre ana depodan bu jdk' ları rahatlıkla indirip kurabilirsiniz. Örneğin RHEL tabanlılar için ;
~$ sudo dnf/yum install java-11-openjdk # or java-latest-openjdk
Veya Debian tabanlılar için
~$ sudo apt install openjdk-11-jdk # or default-jre
Burada önerebileceğim bir başka seçenek ise Belsoft tarafından yayınlanan libertica jdk sürümleridir. Bunlar opensource ve ücretsiz olarak dağıtılan java jdk sürümleridir. Standart ve full paket gibi bir çok seçenekle jdk indirebilir ve kurabilirsiniz. Bir çok işletim sistemine yönelik kurulum scriptleri veya arşivleri [bu sayfada] (bell-sw.com/pages/downloads/#mn) bulabilirsiniz. KNIME Analitic için standart jdk-11-lts yeterlidir. Linux için kullanacağımız tar.gz paketini indirip bir dizine extract edilmelidir. Daha sonra JAVA_HOME ve PATH değişkenleri güncellenerek java kurulumu tamamlanır.
~$ mkdir -p ~/libertica-jdks
~$ tar xvf /path/to/downloaded-jdk.tar.gz -C ~/libertica-jdks/
~$ export JAVA_HOME=~/libertica-jdks/jdk-11.?.?
~$ export PATH=$PATH:JAVA_HOME/bin
## after this
~$ java -version
Bu oturumda jdk kullanılabilir. Eğer sürekli bu konumda kullanmak isterseniz JAVA_HOME ve PATH için export kullanılan satırları .bashrc veya zsh kullanıyorsanız .zshrc dosyanıza eklemelisiniz.
Java kurulumundan sonra knime kurulan dizine gidip ./knime scriptini çalıştırmanız yeterlidir. Eğer sisteminizde birden fazla jdk kurulu ise spesifik olarak ./knime -v /path/to/jdk-11/bin ile jdk-11 in yolunu verebilirsiniz.
Eğer bir dektop entry oluşturmak isterseniz bunun için;
[Desktop Entry]
Type=Application
Name=KNIME Analytic Platform
Description=Data Science Environment
Exec=/path/to/knime-folder/knime_4.?.?/knime
Icon=/rpath/to/knime-folder/knime_4.?.?/icon.svg
Categories=Development;Science;
terminal=false
entry'i ~/.local/share/application/knime.desktop isimli bir dosya oluuşturup ilgili lokasyona kaydedebilirsiniz. Eğer exec komutunda problem yaşarsanız. exec komutunda parametre olarak ./knime scriptini çalıştıran bir shell script i verebilirsiniz. Eğer görüntü sunucusu olarak wayland kullanıyorsanız uygulama içinde de problem yaşayabilirsiniz. BU sebeple bashrc veya zshrc veya hangi shell i kullanıyorsanız konfigurasyon dosyanıza veya KNIME'ı başlatan script dosyanınızın içine export GDK_BACKEND=x11 satırını ekleyebilirsiniz. Zaten x11 kullanıyorsanız sorun yaşamayacaksınız. KNIME ı başlatan shell script örneğin;
#/bin/bash
export GDK_BACKEND=x11
./knime -v /path/to/java-jdk-11/bin
şeklinde olabilir.
Extention kurulumları
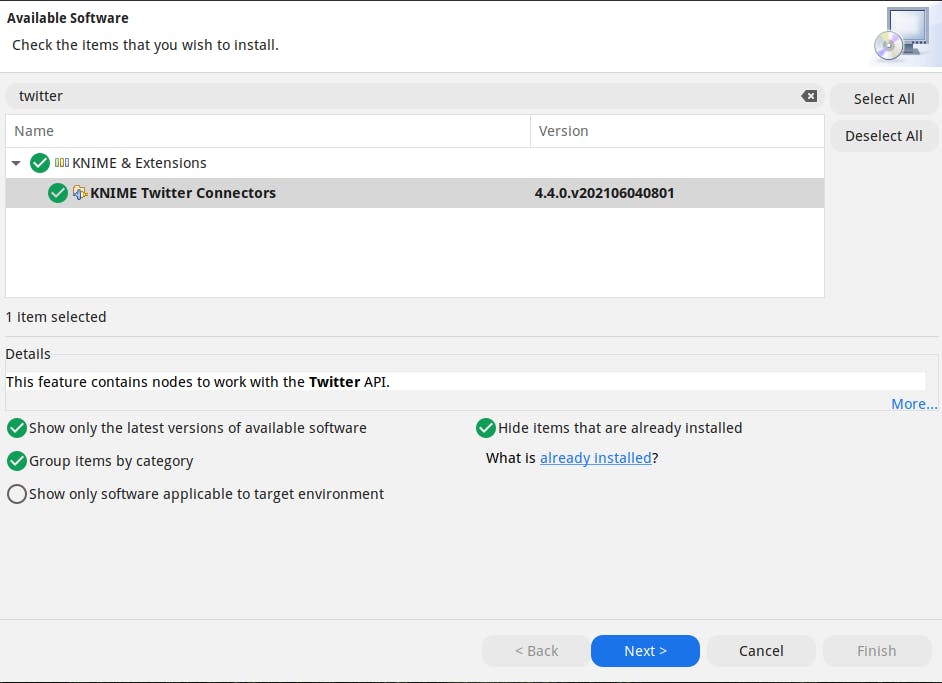
KNIME uygulaması birçok extentiona sahipti.Kullanıcı sayısının fazla olması ve genişletilebilir olması diğer veri madenciliği uygulamaları arasında onu zirveye taşıyan en önemli faktörlerdir. Uygulamada File menüsünden Install KNIME Extentions... seçerek arayüzü açabilirsiniz. İstediğiniz eklentiyi arayarak kurulum yapabilirsiniz. Örneğin Twitter API a bağlanıp veri çekebilmek için kullanılması gereken KNIME twitter connector eklentisini kurabilirsiniz. Gerekli bağımlılık paketleri ile birlikte kurulumu yapılacaktır. Yeni pluginleri okuyabilimesi için uygulmamanın yeniden başlatılması gerekecektir.
Ardından Node Repository bölümünden istediğiniz düğümü arayarak projenize ekleyebilirsiniz.
KNIME ile Makine Öğrenmesi Uygulaması
Bu bölümde bir makine öğrenmesi uygulaması hazırlamak için bir adet hazır bir veri seti kullanılacaktır. UCI Machine Learning Repository sinde bulunan HCV Data Dataset isimli verisetini kullanılarak KNME nodeları ile bir veri madenciliği workflow'u oluşturulacaktır. File menüsünden new project ile proje oluşturulur. Node Repository
bölümünden file reader veya csv reader arayarak dosyamı projeye ekliyorum. Benzer şekilde yapmak istedğim işlemleri Node Repository'de arayarak projeme ekleyip çalıştırıyorum ve her işlem sonunda çıktıyı bir sonraki node'un girdisi olarak veriyorum.
Düğümlere sağ tıkladığımda yapılan işlemi konfigure edip daha sonra çalıştırıyorum. Yine sağ tıkladığımda menünün altında işlem sonucunda düğümün çıktılarını görebiliyorum. Aşağıdaki Normalize düğümü normalize edilmiş tabloyu ve modeli çıktı olarak sunmakta.
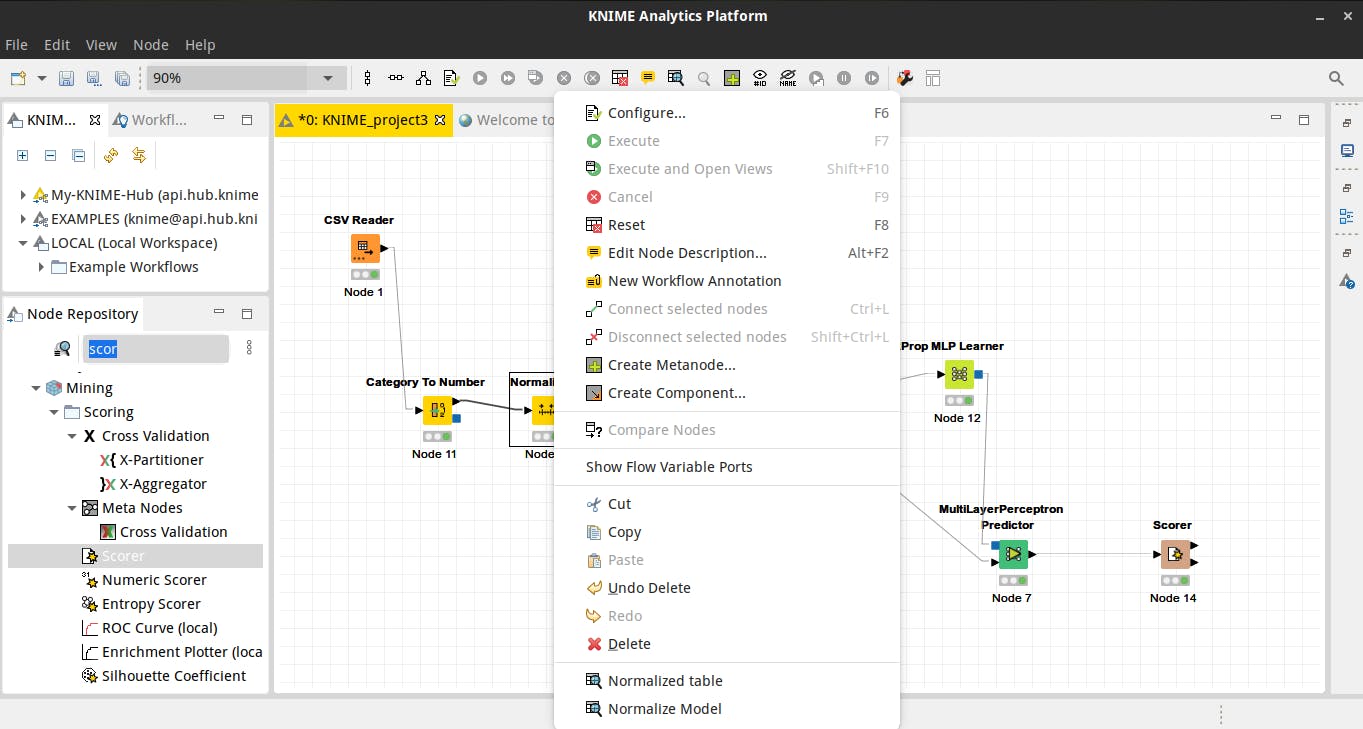
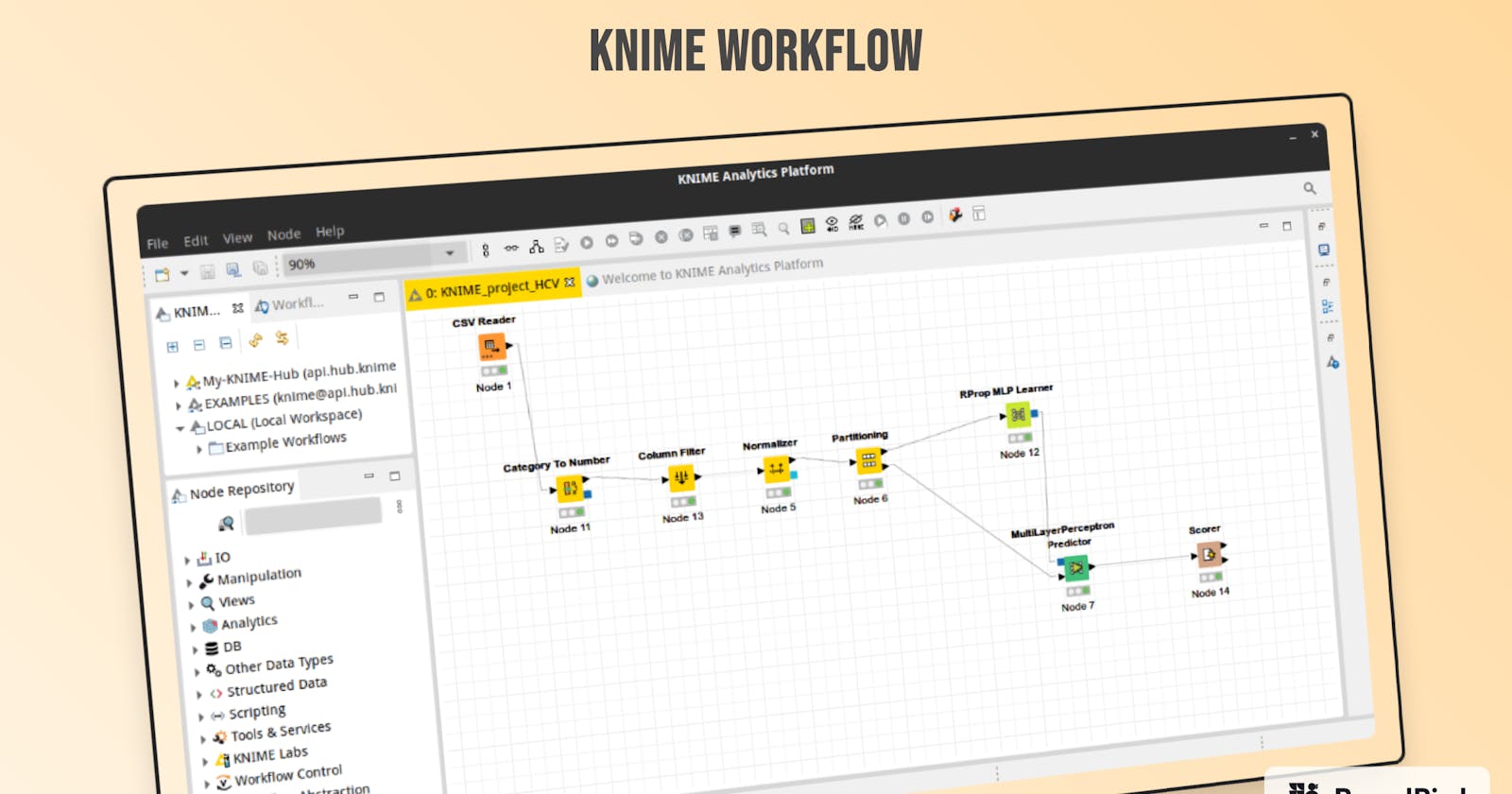
Bu uygulamada yapılan işlemlere aşağıdaki şekilde görülebilmektedir.
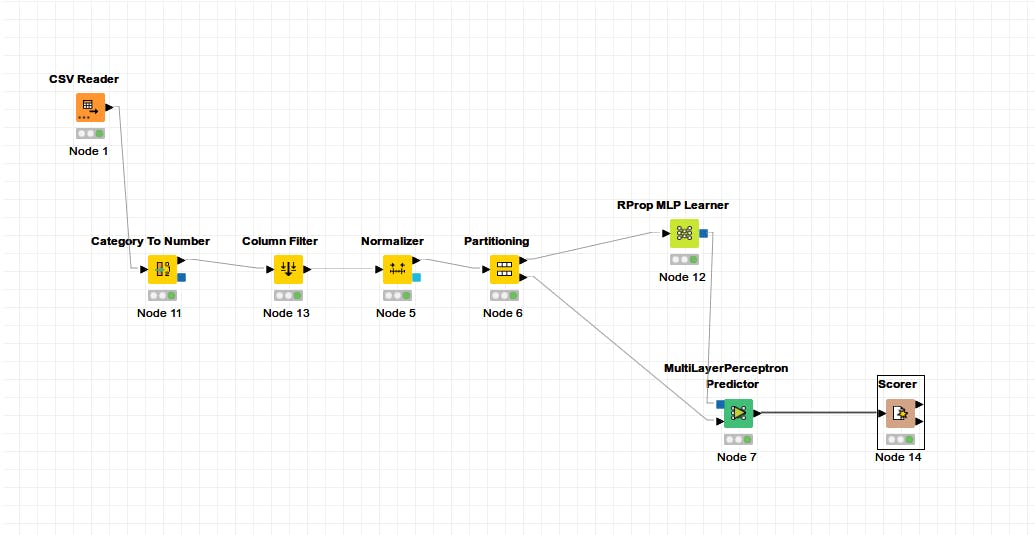
Uygulamada önce csv dosyasındaki veriler csv reader düğümü ile okunarak içindeki sex gibi kategorik değerler sayıya dönüştürülmesi için category to number düğümüne verildi. Bu düğümün çıktısı Id ve kategorik cinsiyet değerlerinin çıkarımlası için column filter düğümüne verildi. Çıktı olarak alınan veriseti Normalize düğümüne verildi. 0-1 normalizasyonu uygulanan veriseti %70 eğitim, %30 test olarak ayrılmak üzere Partitioning düğümüne verildi. Parçalardan eğiitim veriseti RProp MLP Learner düğümüne verilerek bir model oluşturuldu. Bu model ve test veriseti MultiLayerPerceptron Predicter düğümüne verilerek test edildi. Ve düğümün çıktısı Scorer düğümünde karşılaştırma matrisi ve başarımla ilgili score değerlerinin bulunduğu tabloya dönüştürüldü.
Perceptron modelimiz 1 hidden layer ve 10 nöron ile denendiğinde görüldü ki sırasıyla karşılaştırma matrisimiz ve başarım değerlerimiz;
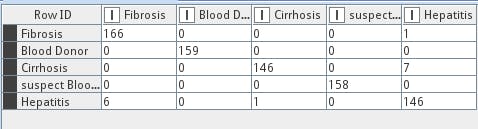

olarak karşımıza çıkmakta. Oldukça başarılı bir model olduğu görülmekte fakat burada kullandığımız veriseti ham veri değildi. Veri seti üzeride veri ön işleme adımları uygulanmış halinin performansı %98 accuracy olarak karşımıza çıktı. Önişleme başarımı kesinlikle artıran bir faktördür. Eğer sizde ham veri seti ile direct olarak model oluşturursanız bu seviyede bir başarıma ulaşamadığını görebilirsiniz.
Bu verisetine uygulanan ön işleme adımları sırasıyla;
- R ile eksik verilerin temizlenmesi
- Smote ile ovesample veriseti dengeleme
- R boxplot ile outlier temizliği
- İkinci defa SMOTE ile veriseti dengeleme
Bu proje ve verisetini linkteki repo da bulabilirsiniz.